SBI-ACR BREAST IMAGING SYMPOSIUM 2023
Hyunkwang Lee, PhD
Purpose
Double reading of screening mammograms provides performance advantages over single reading, but the strain on resources makes it prohibitively expensive in many locations such as the United States. One way to gain the benefits of double reading despite limited resources would be to instead use deep learning-based AI to aid radiologists. The purpose of this study was to examine whether the performance benefits provided by categorical AI are comparable to double reading.
Materials and Methods
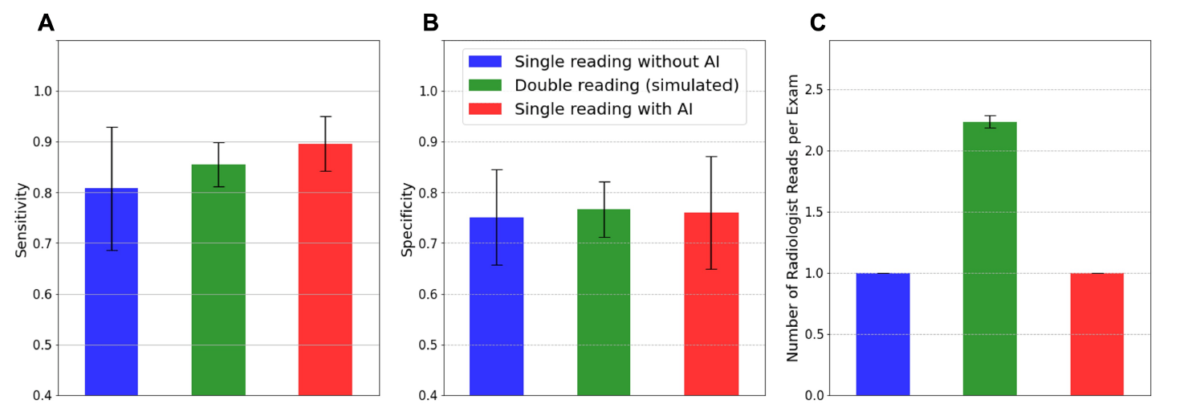
Data for this study came from a previously-described reader study, which evaluated the performance of 18MQSA-qualified radiologists (9 general radiologists and 9 breast imaging specialists) interpreting screening DBT mammograms. Readers in the study interpreted 240 retrospectively collected exams (100 cancer and140 non-cancer) once without and once with the aid of categorical AI, a novel custom-build software designed to detect breast cancer in screening mammograms. The mean sensitivity and specificity across all radiologists were calculated both without and with the use of AI. Additionally, double reading was simulated by comparing the interpretations of two independent readers for a given exam. If the two readers disagreed,the final interpretation outcome was determined by using the results of a third adjudicating breast imaging specialist. All combinations of first, second and adjudicator interpretations were simulated and the mean sensitivity, specificity, and radiologist workload (number of radiologist reads per exam) were calculated.
Results
Single reading with AI (89.6% sensitivity) showed improved sensitivity over single reading without AI (80.8%sensitivity) and simulated double reading (85.6% sensitivity). Single reading with AI did not reduce specificity(76.0% for single reading with AI, 75.1% for single reading without AI, 76.7% for simulated double reading).Additionally, AI’s improvement was achieved without any increase in radiologist workload, whereas double reading (2.23 radiologist reads per exam) would require 123% additional radiologist workload compared to single reading (1 radiologist read per exam). The performance improvements when using AI over simulated double reading held for specialists, indicating improvement even over having specialists double read (92.3%sensitivity and 75.1% specificity for single reading by specialists with AI, 88.8% sensitivity and 72.9% specificity for simulated double reading with specialists).
Conclusion
Categorical AI helped radiologists improve performance even more than double reading without requiring any additional radiologist workload.
Clinical Relevance
Categorical AI can help radiologists perform at least as well as double reading without the substantial increase in radiologists’ time that accompanies double reading.