SBI-ACR BREAST IMAGING SYMPOSIUM 2023
Bryan Haslam, PhD
Purpose
Several AI models have been FDA-cleared for aiding detection and diagnosis of cancer in screening mammography. Though performance of these models is promising, the data reported is often retrospective and limited in scale. Here we sought to evaluate performance of categorical AI that was tested prospectively in a large population by comparing the AI outputs to the interpreting radiologists’ performance.
Materials and Methods
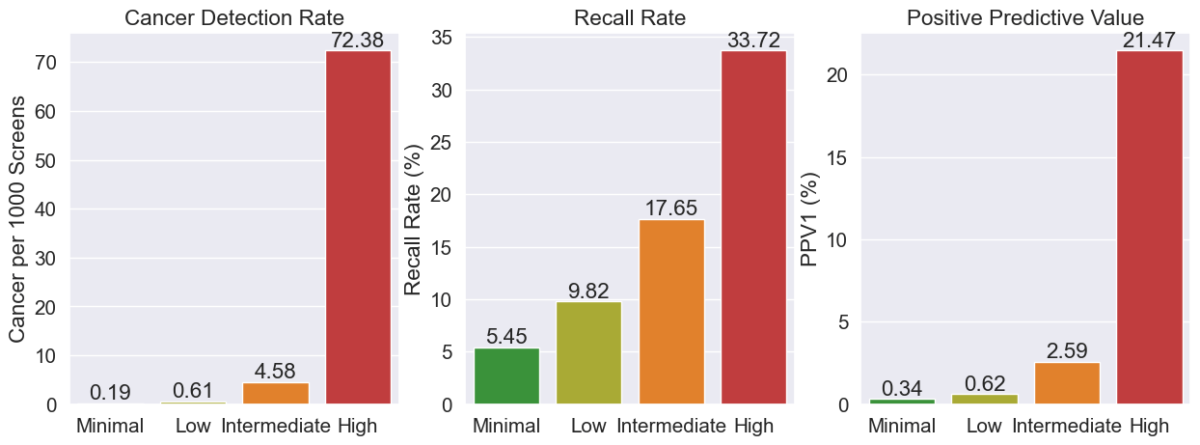
A categorical AI model was deployed at 151 clinical sites across the USA. AI results were generated for 519,281 screening mammograms interpreted by 223 MQSA-qualified radiologists over more than 10 months. The data collected for each mammogram included the raw AI numeric scores, radiologists’ BIRADS assessments, and all biopsy outcomes within 6 months of imaging. The AI scores were also binned into four suspicion categories using specified thresholds in the order of least to most suspicious such that the categories contain ~25% (“Minimal”), ~50% (“Low”), ~20% (“Intermediate”) and ~5% (“High”) of all mammograms. Cancer detection rate (CDR), abnormal interpretation or recall rate (RR), and positive predictive value (PPV1) were assessed for the mammograms in each suspicion category.
Results
The observed CDR increased exponentially with increasing AI suspicion category (0.19, 0.61, 4.58 and 72.38), while the recall rate increased only incrementally with AI suspicion category (5.45, 9.82, 17.65, 33.72). PPV1 also increased exponentially (0.34, 0.62, 2.59, 21.47). In particular, the PPV1 for the Minimal and Low categories was much lower than minimum recommendations (>= 3%) from national guidelines and much lower than any radiologists in BCSC’s benchmark data (0.8%), suggesting that many radiologists may not yet grasp the specific numbers underlying these categories and therefore be recalling too many patients in these categories for the number of cancers being detected.
Conclusion
In a group of more than half a million patients, AI was able to reliably categorize screening mammograms using four cancer suspicion categories. Given the dramatic difference in performance at the different suspicion categories, radiologists could potentially increase CDR by adjusting their behavior to focus on High and Intermediate exams while also lowering recall rates by up to 50% through reducing recalls on Minimal and Low exams, which only represented 7% of all cancers. A reduction in recall rates for these exams would also help increase PPV1 to be closer to recommendations.
Clinical Relevance
AI for mammography can indicate cancer suspicion reliably to clinicians as supported by large scale clinical data. Changing behavior by suspicion category could lead to quality improvements for patients.